误差反向传播法
1.计算图
无论全局是多么复杂的计算,都可以通过局部计算使各个节点致力于简单的计算,从而简化问题
另外,利用计算图可以将中间的计算结果全部保存起来
其最大的优势在于,可以通过反向传播高效计算导数
反向传播传递的是局部导数
下面是,支付金额关于苹果的的价格的导数
就是总的金额,220/220 = 1,220/200 = 1.1,220/100=2.2
计算中途求得的导数的结果(中间传递的导数)可以被共享,从而可以高效地计算多个导数
计算图的优点是,可以通过正向传播和反向传播高效地计算各个变量的导数值

2.链式法则
如果某个函数由复合函数表示,则该复合函数的导数可以用构成复合函数的各个函数的导数的乘积表示,这就是链式法则
反向传播是基于链式法则的
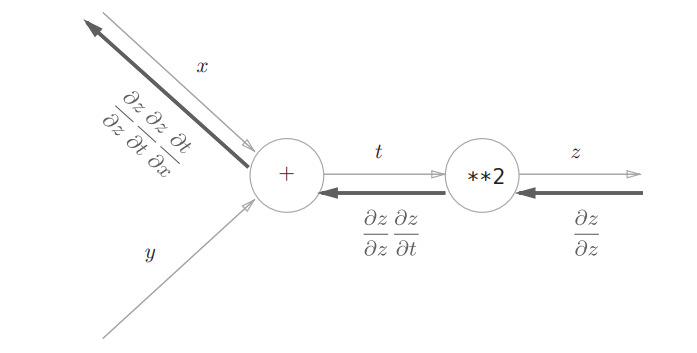
3.反向传播
加法节点的反向传播,只是将输入信号输出到下一个节点,输入的值会原封不动地流向下一个节点
乘法节点的反向传播,会将上游的值乘以正向传播时的输入信号的“翻转值”后传递给下游,翻转值表示一种翻转关系
乘法的反向传播需要正向传播时的输入信号值,实现乘法节点的反向传播时,要保存正向传播的输入信号
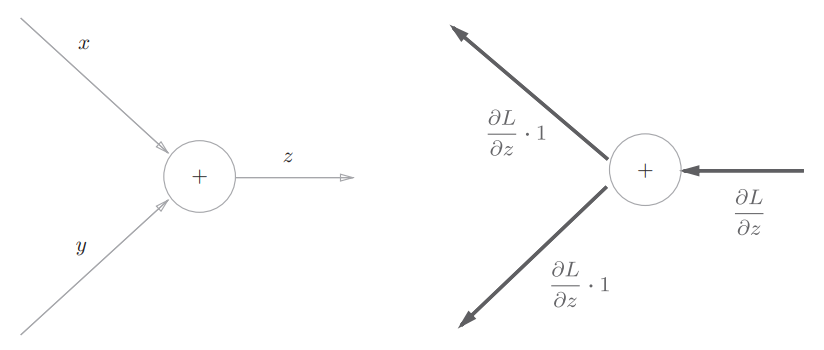
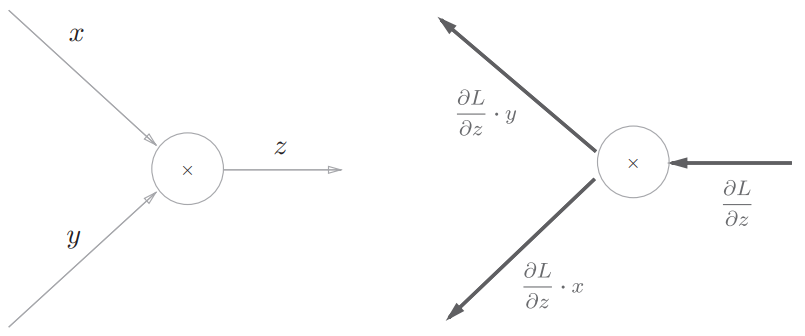
4.简单层的实现
层,是神经网络中功能的单位,如负责sigmoid函数的sigmoid,是以层为单位进行实现的,通常,用一个类来实现一个层
5.激活函数层的实现
ReLU层
表达式如下
求导之后
如果正向传播时的输入x大于0,则反向传播会将上游的值原封不动地传给下游,如果正向传播时的x小于等于0,则反向传播中传给下游的信号将停在此处
Sigmoid层
表达式如下
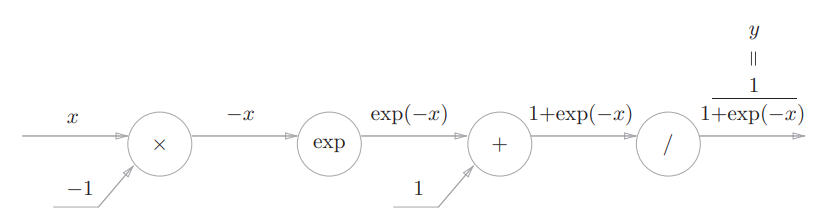
计算图表示表达式如下(正向传播)
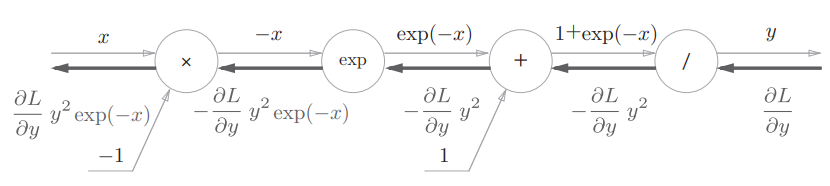
反向传播
观察到反向传播的输出,可以根据正向传播的输入x和输出y计算出来
另外, $\frac {\partial L}{\partial y} y^2 exp(-x)$ 可以进一步整理
此时,反向传播的输出可直接根据正向传播的输出y就能计算出来
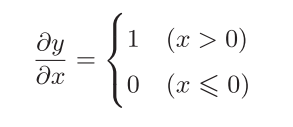
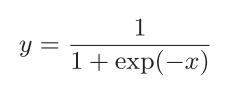
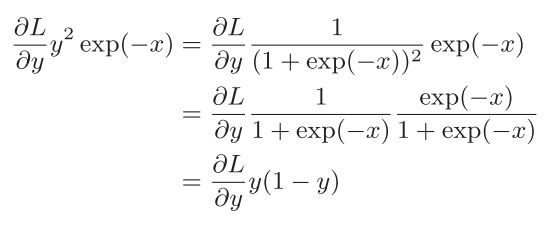
6.Affine层/Softmax层的实现
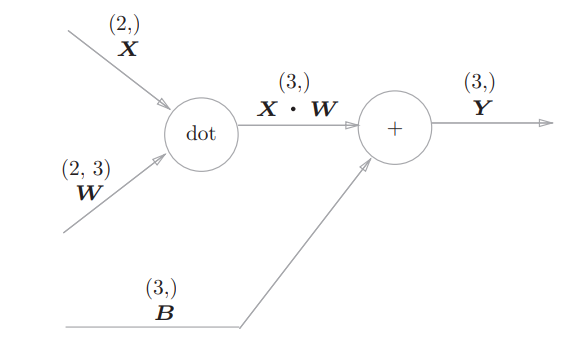
Affine层(全连接层)
神经网络的正向传播中进行的矩阵的乘积运算在几何学领域被称为“仿射变换”,将进行仿射变换的处理实现为“Affine层”,本质就是 $y = xW + b$ ,表示一个线性变换
几何中,仿射变换包括一次线性变换和一次平移,分别对应神经网络的加权和运算与加偏置运算
在神经网络中使用的是 dot 进行矩阵乘积运算,Affine层的计算图如下(正向传播)
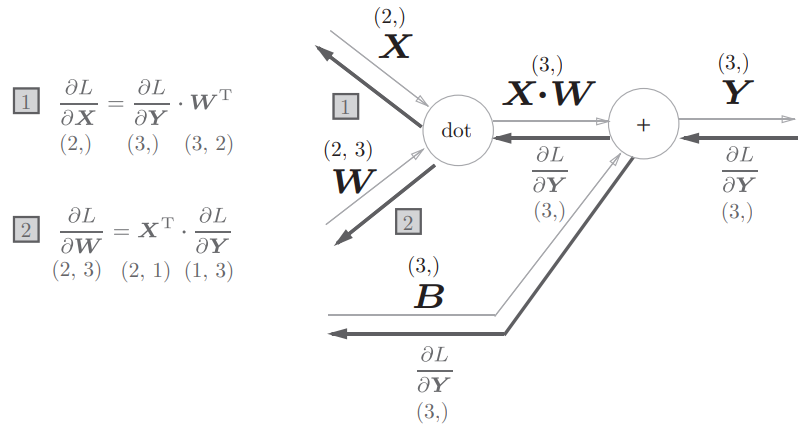
反向传播
注意上面反向传播的两个输出,W 和 X 的位置是不同的
另外,这里输入的 X 是以单个数据为对象的
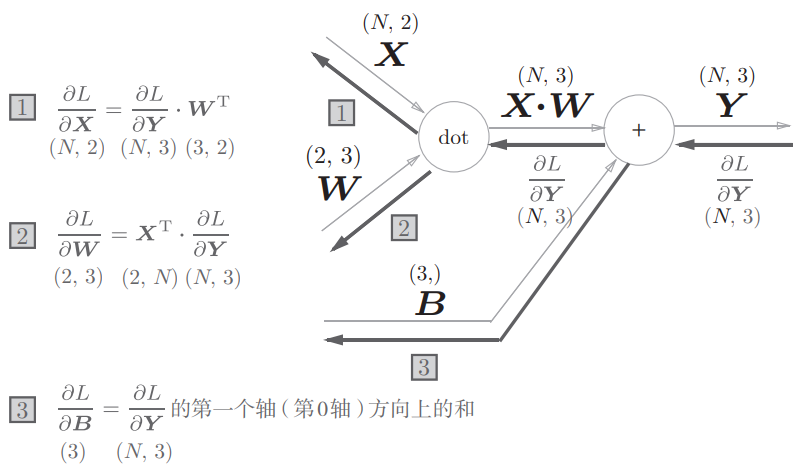
批版本的Affine层
考虑N个数据一起进行正向传播,就要使用 batch,batch版的Affine层计算图如下
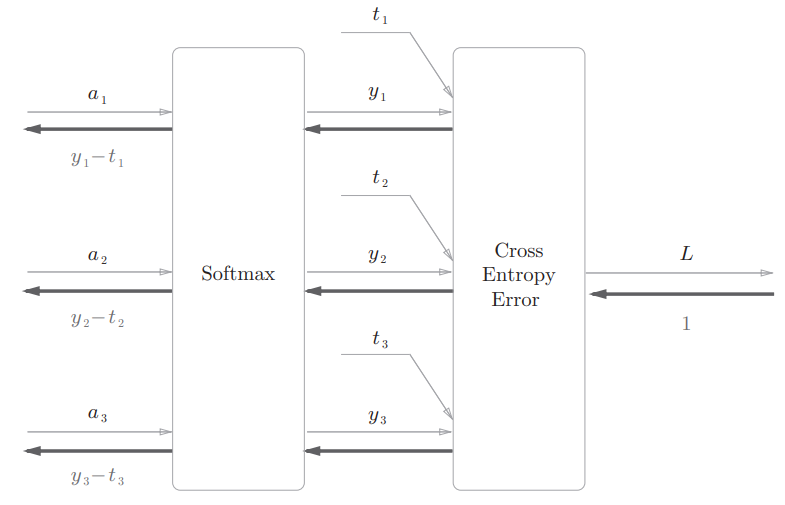
softmax-with-loss层
神经网络中未被正规化的输出结果有时被称为得分
当神经网络的推理只需要给出一个答案的情况下,因为此时只对得分最大值感兴趣,所以不需要 Softmax层
因为是包含损失函数的交叉熵误差,所以叫做Softmax-with-Loss层,计算图如下
7.误差反向传播的实现
误差反向传播法的梯度确认
数值微分虽然计算狠很耗费时间,但它的优点是实现简单,因此,一般情况下不太容易出错;而误差反向传播法虽然计算很快,但它的实现很复杂,容易出错。所以,经常会比较数值微分的结果和误差反向传播法的结果,以确认误差反向传播法的实现是否正确
确认数值微分求出的梯度结果和误差反向传播法求出的结果是否一致(严格地讲,是非常相近)的操作称为梯度确认(gradient check)
code
简单层的实现
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
"""
实现了神经网络中的两个基础层:
1. MulLayer: 乘法层,用于实现两个数的乘法运算
2. AddLayer: 加法层,用于实现两个数的加法运算
这些层都实现了前向传播(forward)和反向传播(backward)方法
"""
class MulLayer:
"""
乘法层的实现
用于计算两个数的乘积,并支持反向传播
"""
def __init__(self):
# 初始化存储输入值的变量
self.x = None # 存储第一个输入值
self.y = None # 存储第二个输入值
def forward(self, x, y):
"""
前向传播:计算两个数的乘积
参数:
x: 第一个输入值
y: 第二个输入值
返回:
out: x和y的乘积
"""
self.x = x # 保存输入值,用于反向传播
self.y = y
out = x * y # 计算乘积
return out
def backward(self, dout):
"""
反向传播:计算梯度
参数:
dout: 上游传来的梯度
返回:
dx: 对x的梯度
dy: 对y的梯度
"""
dx = dout * self.y # 对x的梯度 = 上游梯度 * y
dy = dout * self.x # 对y的梯度 = 上游梯度 * x
return dx, dy
class AddLayer:
"""
加法层的实现
用于计算两个数的和,并支持反向传播
"""
def __init__(self):
# 加法层不需要存储中间值,所以pass
pass
def forward(self, x, y):
"""
前向传播:计算两个数的和
参数:
x: 第一个输入值
y: 第二个输入值
返回:
out: x和y的和
"""
out = x + y # 计算和
return out
def backward(self, dout):
"""
反向传播:计算梯度
参数:
dout: 上游传来的梯度
返回:
dx: 对x的梯度
dy: 对y的梯度
"""
dx = dout * 1 # 对x的梯度 = 上游梯度 * 1
dy = dout * 1 # 对y的梯度 = 上游梯度 * 1
return dx, dy
# 购买2个苹果3个橘子的例子
apple = 100
apple_num = 2
orange = 150
orange_num = 3
tax = 1.1
mul_apple_layer = MulLayer()
mul_orange_layer = MulLayer()
add_apple_orange_layer = AddLayer()
mul_tax_layer = MulLayer()
# forward
apple_price = mul_apple_layer.forward(apple, apple_num)
orange_price = mul_orange_layer.forward(orange, orange_num)
all_price = add_apple_orange_layer.forward(apple_price, orange_price)
price = mul_tax_layer.forward(all_price, tax)
# backward
d_price = 1
d_all_price, d_tax = mul_tax_layer.backward(d_price)
d_apple_peice, d_orange_price = add_apple_orange_layer.backward(d_all_price)
d_orange, d_orange_num = mul_orange_layer.backward(d_orange_price)
d_apple, d_apple_num = mul_apple_layer.backward(d_apple_peice)
print(price)
print(d_apple_num)
print(d_apple)
print(d_orange_num)
print(d_orange)
print(d_tax)激活函数层的实现
ReLU层
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
def __init__(self):
self.mask = None
def forward(self, x):
# x <= 0的为true,x>0的为false
self.mask = (x <= 0) # 保存结果,用于反向传播
# out是x的复制
out = x.copy()
# 这一步很关键,mask是一个bool数组,当它作为索引时,会选中True的位置,让后将其置为0,而False的位置不会被选中,就会保持原来的值
# 这就实现了 x <= 0置为0,x > 0保持原值
out[self.mask] = 0
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dx
x = np.array([[1.0, -0.5], [-2.0, 3.0]])
print(x)
mask = (x <= 0 )
print(mask)Sigmoid层
2
3
4
5
6
7
8
9
10
11
12
13
14
def __init__(self):
self.out = None
def forward(self, x):
out = 1 / (1 + np.exp(-x))
self.out = out # 保存输出,用于反向传播
return out
def backward(self, dout):
# 对应的就是 (\partial L/ partial y) * y * (1 - y)
dx = dout * (1.0 - self.out) * self.out
return dxAffine层
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def __init__(self, W, b):
self.W = W
self.b = b
self.dW = None
self.db = None
def forward(self, x):
self.x = x # 保存输入,供反向传播用
out = np.dot(x, self.W) + self.b # b使用到了广播机制
return out
def backward(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
return dx需要说明的是,backward中,分别表示了 $\frac {\partial L} {\partial X} = \frac {\partial L}{\partial Y} W^T$ ,$\frac {\partial L} {\partial W} = X^T \frac {\partial L}{\partial Y}$ ,$\frac{\partial L}{\partial B} = \frac{\partial L}{\partial Y}$
Softmax-with-Loss层的实现
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def __init__(self):
self.loss = None # 损失
self.y = None # softmax的输出
self.t = None # 监督数据(one-hot vector)
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
dx = (self.y - self.t) / batch_size
return dx误差反向传播的实现
误差反向传播的神经网络的实现
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
sys.path.append('../../py_pro/DL/')
import numpy as np
from common.layers import *
from common.gradient import numerical_gradient
from collections import OrderedDict
from dataset.mnist import load_mnist
from ch04.two_layer_net import TwoLayerNet
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
# 生成层
# OrderedDict是有序字典,会记录往字典中添加元素的顺序
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['ReLU1'] = Relu()
self.params['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.lastLayer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1 : t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
def numerical_gradient(self, x, t):
loss_W = lambda W : self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
grads = {}
grads['W1'] = self.layers['Affine1'].dW
grads['b1'] = self.layers['Affine1'].db
grads['W2'] = self.layers['Affine2'].dW
grads['b2'] = self.layers['Affine2'].db
return grads
# 读入数据
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label= True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
x_batch = x_train[:3]
t_batch = t_train[:3]
grad_numerical = network.numerical_gradient(x_batch, t_batch)
grad_backprop = network.gradient(x_batch, t_batch)
# 求各个权重的绝对误差的平均值
for key in grad_numerical.keys():
diff = np.average( np.abs(grad_backprop[key] - grad_numerical[key]) )
print(key + ": " + str(diff))使用误差反向传播的学习
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
from ch05.two_layer_net import TwoLayerNet
# 读入数据
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 通过误差反向传播法求梯度
grad = network.gradient(x_batch, t_batch)
# 更新
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(train_acc, test_acc)