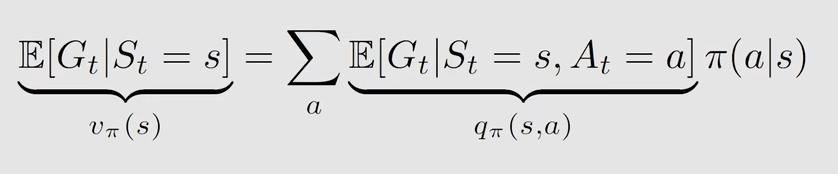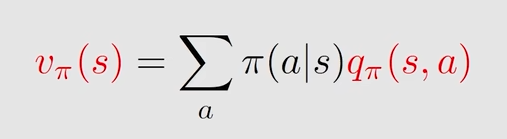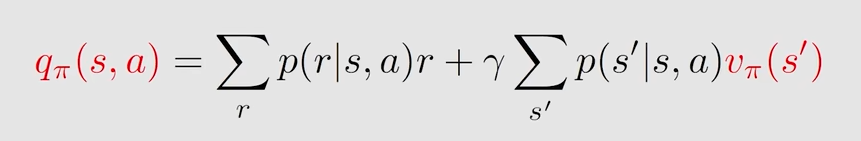贝尔曼方程
第一部分——return
return 能够作为策略好坏的一个评估标准
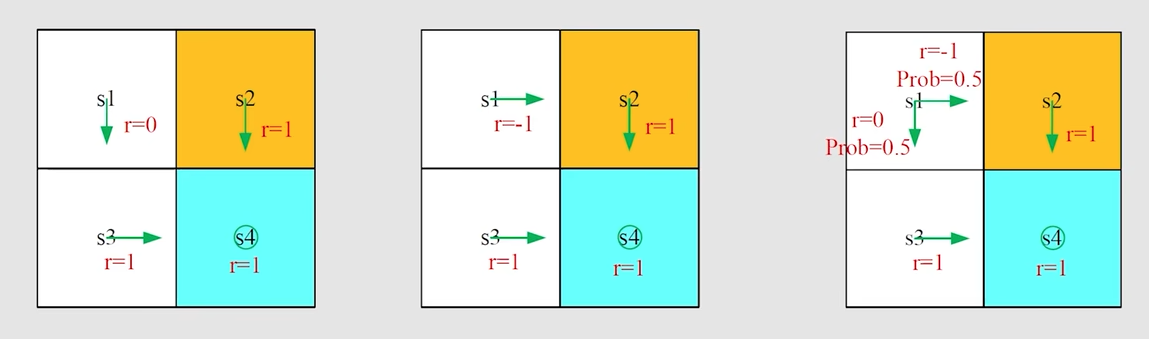
下面通过三种情况来说明这个问题
第一种策略
按照策略1,从 s1 出发,往下去 s3,再往右到达 s4,discounted return计算如下
gamma 是衰减系数
第二种策略
第三种策略
注意,严格说来,这个return3 已经不是我们所说的return了,因为return是针对一条轨迹定义的,针对一个trajectory定义的,这里实际上是有两个轨迹,这里所做的是求取平均值,也即求expectation(期望),这个return3就是state value
显然,return1 > return3 > return2,那么对应的就是策略1最好,策略3居中,策略2最差
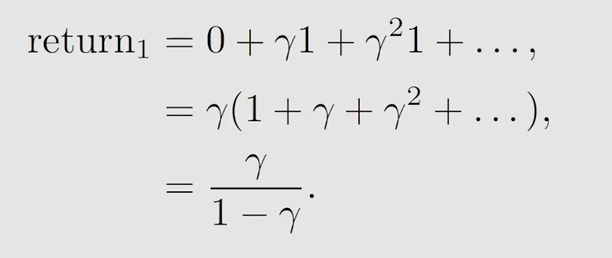
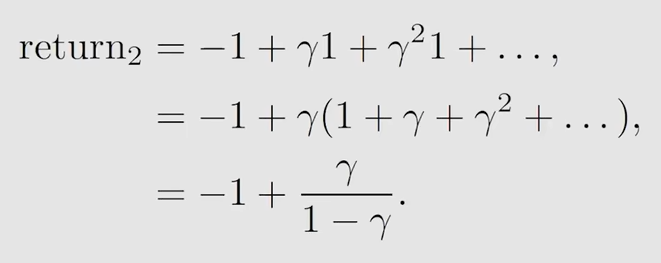

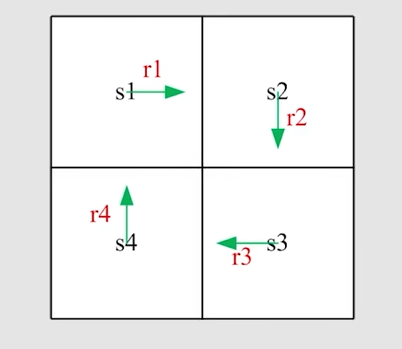
第二部分——return的计算
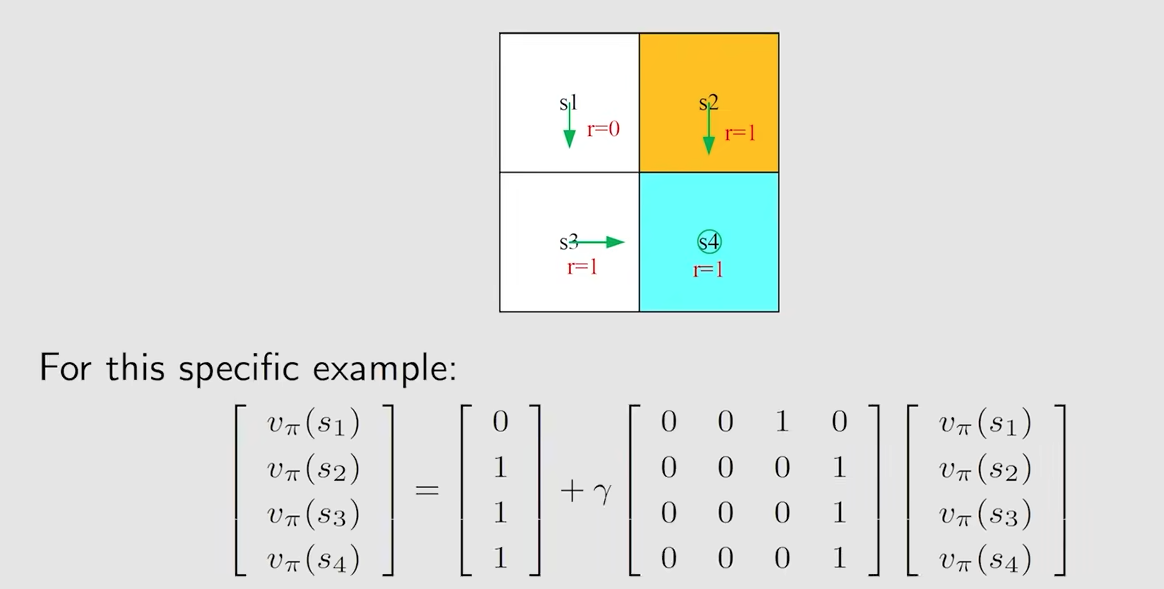
以图中的例子为例
用 v_i来表示从 s_i 出发对应的return
方法一
方法二
这里的方法二说明了什么一个问题呢,从当前状态出发,return的值,就等于当前的reward + 下一状态的return * 衰减因子gamma,也就是说从一个状态出发,它的return是依赖于其他状态的return的,这种思想在强化学习中被称之为 bootstrapping,这种思想是从自身出发,不断迭代所得到的结果
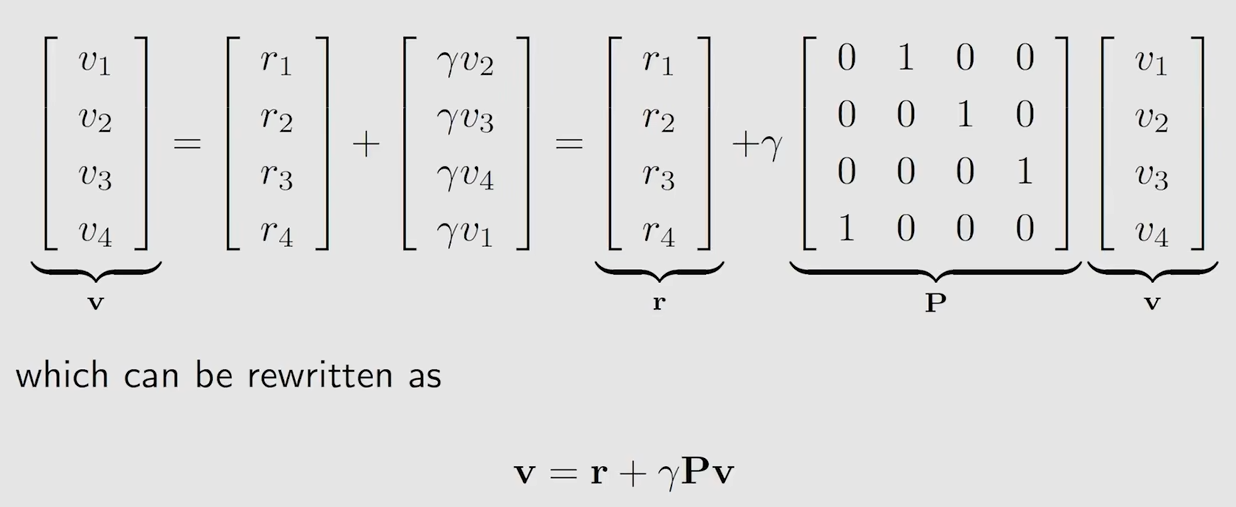
通过矩阵的形式给出上面的四个式子
对该式子进行求解得到 v,实际上这个式子就是 贝尔曼方程,但这是一个非常简单的贝尔曼方程

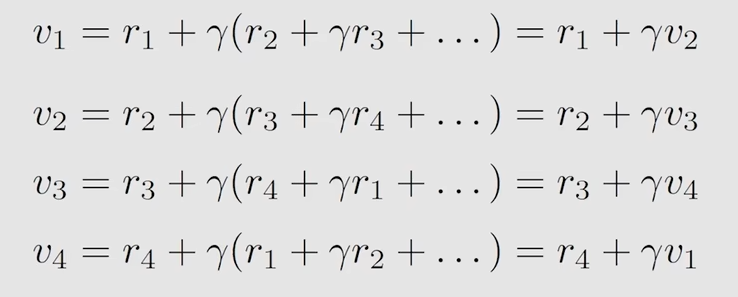
第三部分——state value
先来看一个单步的过程
$$
S_t \xrightarrow{A_t} R_{t+1}, S_{t+1}
$$在这个过程中,都存在一个条件概率
再来看一个多步的过程 trajectory
$$
S_t \xrightarrow{A_t} R_{t+1}, S_{t+1} \xrightarrow{A_{t+1}} R_{t+2}, S_{t+2} \xrightarrow{A_{t+2}} R_{t+3}, \ldots
$$其对应的 discounted return如下
$$
G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \ldots
$$这里的G_t 也是一个随机变量
正式介绍 state value
state value 实际上就是 G_t 的期望值(expectation)或平均值
$$
v_\pi(s) = \mathbb{E}[G_t | S_t = s]
$$它是关于状态s的一个函数,所以在不同状态下,对应不同的G_t也对应不同的 state value
另外,它也是关于策略pi的函数,也可以写为 v(s , pi),不同的策略会得到不同的轨迹,从而得到不同的G_t
state value不仅仅是一个数值,当其值很大时,说明当前状态具有很高的价值
return 与 state value的区别
return是针对单个trajectory而言的,单个trajectory的return(对应的是一种确定性,如拓扑图)
state value是针对多个trajectory而言的,它是多个trajectory的return的平均值(对应的是一种随机性)
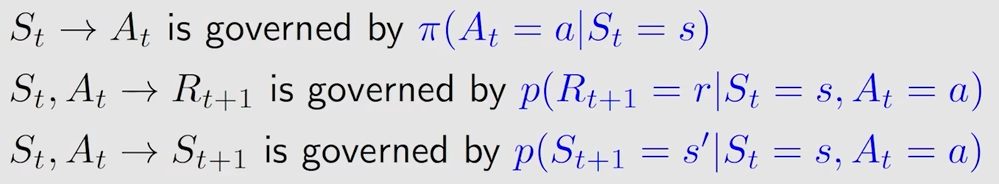
第四部分——贝尔曼公式的推导
贝尔曼公式就是用来计算上一部分提到的state value,它描述了不同状态下state value之间的关系
考虑这样一个trajectory
$$
S_t \xrightarrow{A_t} R_{t+1}, S_{t+1} \xrightarrow{A_{t+1}} R_{t+2}, S_{t+2} \xrightarrow{A_{t+2}} R_{t+3}, \ldots
$$对应的G_t(discounted return)可以表示为
对应的v( s, pi)(state value)可以表示为(贝尔曼公式)
上面的表达式中的第一项的详细表示
在状态s下,采取行动a之后所得到的即时奖励r的期望值
在当前状态s下,有多个可采取的action,每个action对应的一个概率 pi
当采取action a,所得到的value就是
$$
\mathbb{E}[R_{t+1} | S_t = s, A_t = a]
$$也等同于
$$
\sum_{r} p(r | s, a) r
$$它的意思是,在状态s下,采取动作a,得到的即时奖励r的概率为p,最后乘以r本身
所以这整个第一项的期望就是这么求来的,它实际上就是所能得到的即时奖励r的期望值
第二部分的详细表示
在当前状态s下,下一个时刻的return的期望值
这里隐含了一个马尔科夫性,即下一状态,只取决于当前状态,与当前状态之前的状态无关
其余的变换都是概率论中的一些技巧
然后就是正式给出贝尔曼公式的表达式(看起来好复杂!)
它描述了不同状态的state value之间的关系,如上面所示,左边是s的state value,右边的式子包含s’的state value
另外,这是针对一个状态空间而言的,对应的可能是多个式子多个s,而不是一个单一的式子
其求解思想就是 bootstrapping,还依赖于几个概率,第一个是概率是policy,求解出 state value就是在评估策略的好坏,后面两个概率对应的是两个model,dynamic model或 environment model,这里的model可能是已知的也可能是未知的(model free RL)
通过一个例子深入理解贝尔曼公式
先来s1的state value
先看第一个式子,在状态s1下采取动作a3的概率是1,不采取a3的概率是0,也就是说必然采取a3,那么第一部分就等于 1
第二个式子,在状态s1下采取动作a3后状态转换为s3的概率是1,不为s3的概率为0,也就是说状态必然转换为s3,所以第三部分的值为v_pi(s3)*gamma
第三个式子,在状态s1下采取动作a3后获得的即时奖励r=0的概率是1,r不等于0的概率是0,所以第二部分的值为0
此时s1的state value对应的的贝尔曼公式为
$$
v_{\pi}(s_1) = 0 + \gamma v_{\pi}(s_3)
$$这里所得到的形式,过程虽然复杂,但实际上就是跟 第二部分中(return的计算)方法二的表达式是一个道理,那么根据这个思想,就可以直接得出其他几个状态下的state value的贝尔曼公式
有了这几个方程组,就可以通过矩阵的思想来求解了(也可以采取其他办法),得到的结果如下
当 gamma 取某个值时,上面的式子也会对应有一个确定的值,而这个值的大小就说明了那些状态是值得去探索的
计算得到 state value 之后,根据其反映出来的情况,就可以根据需要去改进策略(policy evaluation),不断的改进策略以得到最优策略
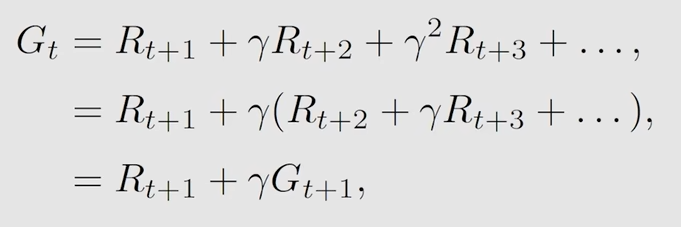
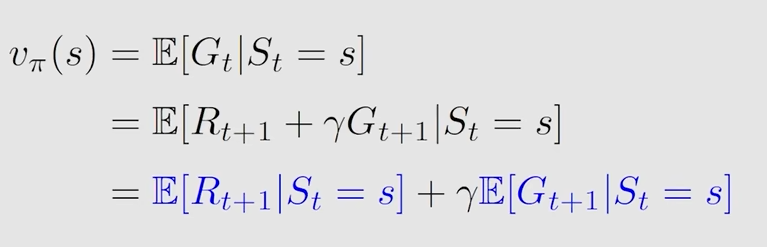
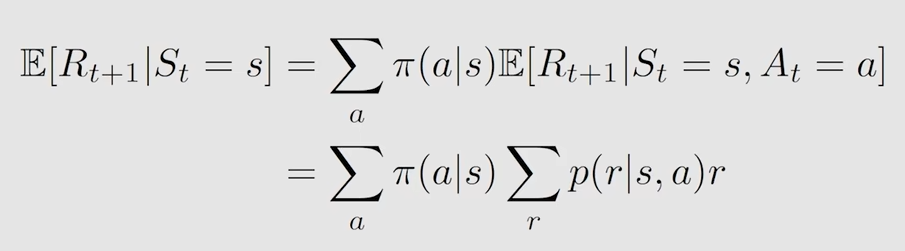
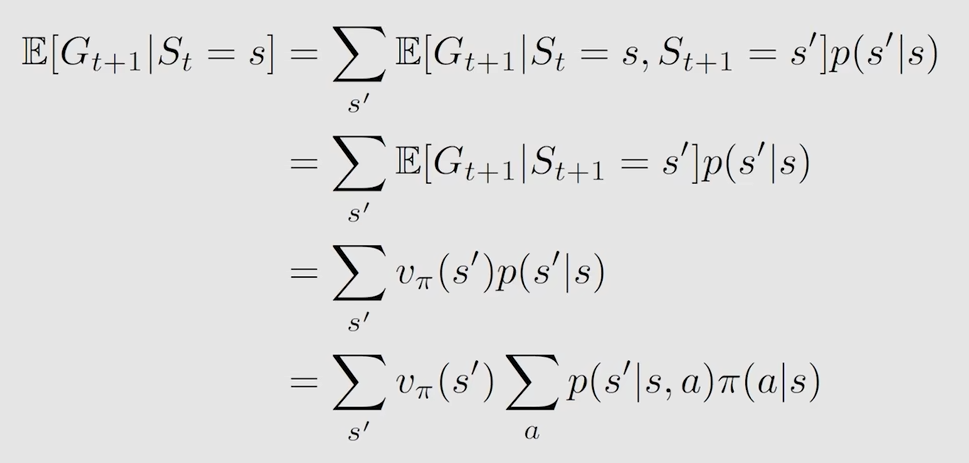
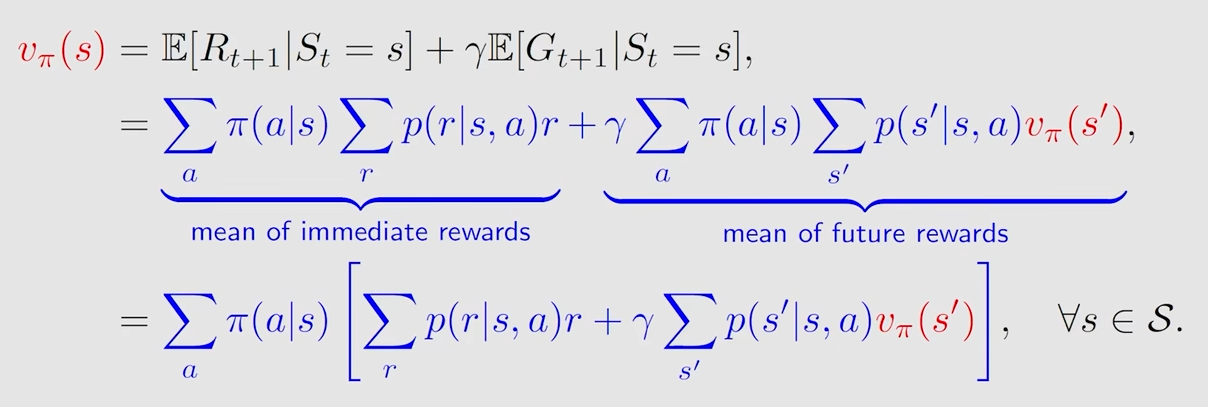

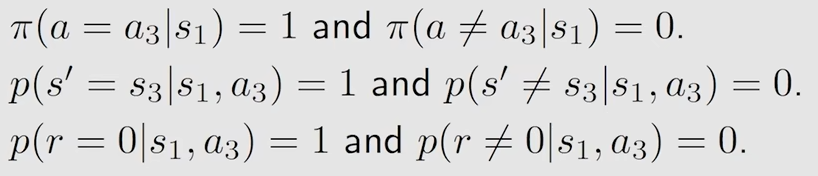
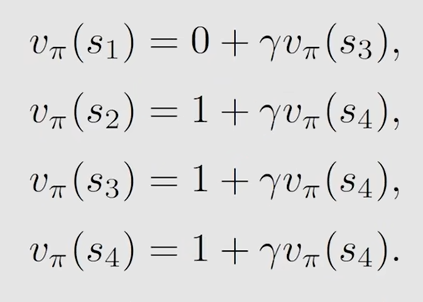
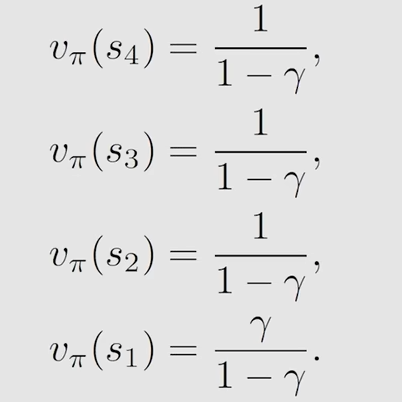
第五部分——贝尔曼公式的矩阵和向量形式
贝尔曼公式是针对一个状态空间而言的,所以自然而然的与矩阵产生关联
将贝尔曼公式的形式进行一个变换,先看贝尔曼公式最初的形式
将其改写为
改写后的式子,第一部分表示的是:从当前状态s出发,所能得到的即时奖励r的平均值(期望)
再将上面改写后的形式进一步简化为
$$
v_{\pi} = r_{\pi} + \gamma P_{\pi} v_{\pi}
$$其中
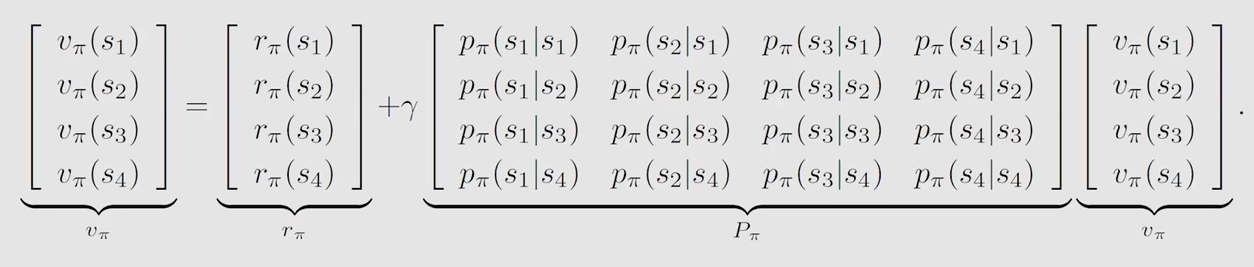
举一个n=4的例子
上式右边第一部分 r_pi 表示:从状态s出发获得的即时奖励r的期望(平均值)
第二部分中前一个矩阵 P_pi 表示:从状态s_i转换为s_j的概率
给定一个policy,可以列出一个与之对应的贝尔曼公式,通过对贝尔曼公式进行求解得到 state value,这样的过程就称之为 policy evaluation,通过评估一个策略的优劣,进而去改进策略,最终得到最优策略
求解贝尔曼方程的常用方法(求逆的方法通常不推荐,因为当矩阵维数很大时,求逆的计算量很大)
常用的是迭代法求解
$$
v_{k+1} = r_{\pi} + \gamma P_{\pi} v_{k}
$$从 v_0开始,可以先假定一个值,然后就可以求出v_1,通过v_1又求出v_2,以此类推,求得v_k,v_k+1,最后就会求出这样一个序列,v_0,v_1…v_k,当 k 趋近于无穷时,就有
v_k收敛到了v_pi,证明如下
其证明过程类似于李亚普诺夫函数的稳定性证明
在下面这样一个例子中,说明了一些情况
可以发现,越靠近目标区域的状态的state value越大,反之则越小
另外就是,不同的策略可能会得到相同的state value
通过计算state value可以评估一个策略的优劣
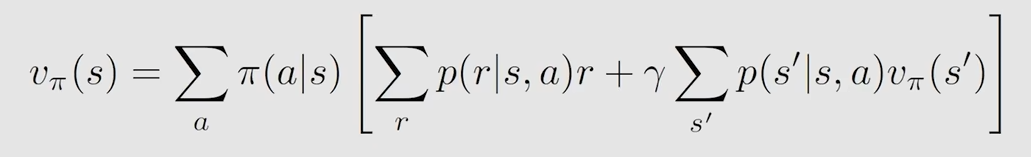
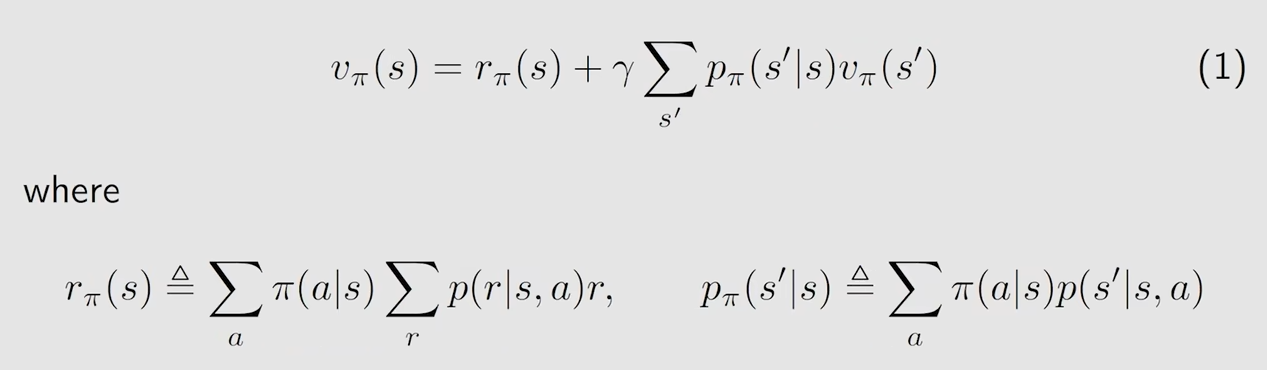
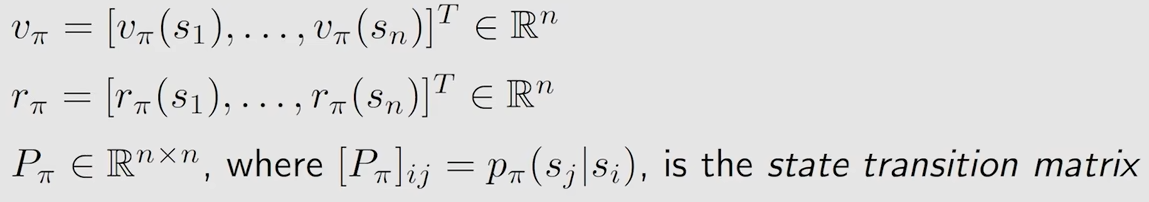
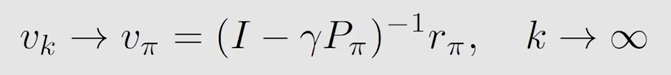


第六部分——Action value
state value 和 Action value 的联系与区别
前者是agent从一个状态出发,所获得的return的平均值(期望)
后者是agent从一个状态出发并且选择了一个Action之后,所获得的returen的平均值(期望)
为什么要引入action value,因为一个状态的转换是选择了一个Action之后引起的
定义
它依赖策略pi
它与state value 数学式上的联系,state value可以表示为下面这个形式
在一个状态下,可能有多种可选的动作,每个动作都有对应的概率,上式右边部分表示,在状态s下,选择动作a后的所获得的return的平均值 * 在状态s下选择动作a的概率
注意到,右边的前面一部分就是 action value的定义,所以二者数学式的联系如下
这个式子说明什么呢,说明了已知一个状态的 action value,对其求平均就可以求出其对应的 state value
另外呢,根据前面第五部分开头的表达式可以进一步给出 action value的表达式
而这个式子,它有说明了,已知一个状态的 state value 可以求出其对应的 action value
(没怎么懂,迷迷糊糊的!)