Goal-Driven Autonomous Exploration Through Deep Reinforcement Learning—通过深度强化学习实现目标驱动的自主探索
摘要
本文提出了一种基于深度强化学习(DRL)的自主导航系统,用于在未知环境中进行目标驱动的探索。系统从环境中获取可能的导航方向的兴趣点(POI),并基于可用数据选择一个最优的航路点。机器人根据这些航路点被引导向全局目标,缓解了反应式导航中的局部最优问题。随后,在仿真环境中通过DRL框架学习用于局部导航的运动策略。我们开发了一个导航系统,将该学习到的策略集成到运动规划系统中,作为局部导航层,用于驱动机器人在航路点之间移动,最终到达全局目标。整个自主导航过程中无需任何先验知识,同时在机器人移动过程中会记录环境地图。实验表明,该方法在无需地图或先验信息的情况下,在复杂的静态和动态环境中相较于其他探索方法具有优势。
自主导航系统
用于通过DRL对未知环境进行目标驱动的探索
获取可能导航方向的兴趣点(POI)
根据可用数据选择最佳航路点
缓解反应式导航中的局部最优问题
采用的是TD3算法(双延迟深度确定性策略梯度)
它是在DDPG算法的基础上进行的扩展
DDPG(Deep Deterministic Policy Gradient)深度确定性策略梯度:它是一种同时学习Q函数和策略的方法,它使用非策略数据和贝尔曼方程来学习Q函数,并使用Q函数来学习策略
详细介绍:https://spinningup.openai.com/en/latest/algorithms/ddpg.html#background
DDPG 对超参数和其他调优手段非常敏感,表现常常不稳定,它的一个常见失败模式是:所学习的 Q 函数会严重高估 Q 值,进而导致策略崩溃,因为策略会利用 Q 函数中的误差
而双延迟深度确定性策略梯度算法(TD3)引入三个关键技巧来解决DDPG的问题:
详细介绍:https://spinningup.openai.com/en/latest/algorithms/td3.html
介绍
完全自主的目标驱动探索是一个包含两个方面的问题
首先,探索机器人需要决策去哪一个方向,以最大可能性到达全局目标。在没有先验信息或无法观测到全局目标的情况下,系统需要直接从传感器数据中指示可能的导航方向。从这些兴趣点(POI)中,需要选择一个最优点作为航路点,以最优的方式引导机器人接近全局目标。
其次,在不依赖地图数据的前提下,还需要获得一种适用于不确定环境的机器人运动策略。
这就引入了DRL
但是DRL存在一个问题:DRL具有反应性特征且缺乏全局信息,其容易陷入局部最优问题尤其是在大规模导航任务中表现尤为明显。
DRL的反应性特征
DRL中的大多策略都是基于当前状态做出决策的,也即 reactive policy(反应式策略),也就是具有马尔可夫性
这会导致:
这种策略适用于快速反应、实时避障等场景
全局信息的缺乏
大多数DRL系统的输入都是局部传感器数据(当前位置的摄像头图像、雷达扫描),因此DRL也只能感知局部环境。另外,强化学习RL本身就是一种局部策略的学习方法,它更适合解决的是马尔可夫决策过程MDP问题。还有就是,DRL的训练目标就是最大化累计奖励,而非构建认知地图。
局部最优问题
系统在当前状态下选择了一个看似收益最大(或最短路径)的行为,但这个选择却可能阻碍了其通向真正全局最优解的路径。
本文提出一种完全自主的探索系统,用于在无需人工控制或环境先验信息的情况下实现导航至全局目标。
该系统从机器人周围的局部环境中提取兴趣点(POI),对其进行评估,并从中选取一个作为航路点(waypoint)。
这些航路点用于引导基于深度强化学习(DRL)的运动策略朝向全局目标,从而缓解局部最优问题。
机器人依据该策略进行运动,无需对周围环境进行完整建图。
POI
这里所说的 POI 兴趣点,是指机器人环境中那些具有导航价值的特定点或位置,这些点通常是机器人决策“去哪儿”的候选目标。它们帮助机器人在未知环境里选择下一步行动方向,特别是在没有完整地图信息时。POI 可以作为导航路径的候选点,也即中间航路点waypoint。
POI的确定
激光读数间隙产生的POI:当连续两束激光雷达测距数值差距较大时,说明可能有一个开口或通道,这个位置就被视作一个 POI。
非数值激光读数产生的POI:激光雷达超出测量范围时返回非数值,代表远处有自由空间,这些边缘位置也被标记为兴趣点。
导航系统的实现:左侧展示了机器人的设置,中间和右侧分别可视化了全局导航与局部导航的组成部分及其数据流。

实现
导航结构分两部分:
具有最优航路点选择机制的全局导航与建图模块
基于深度强化学习的局部导航模块
系统首先从环境中提取兴趣点(POI),并依据设定的评估标准选择一个最优航路点。
在每一个导航步骤中,系统会将该航路点以相对于机器人当前位置与朝向的极坐标形式输入神经网络。
随后,网络基于当前的传感器数据计算并执行一个动作,以朝向该航路点运动。
在机器人沿着多个航路点逐步向全局目标移动的过程中,同时完成对环境的地图构建(建图)。
A.全局导航
为了使机器人能够朝向全局目标导航,必须从当前可用的兴趣点(POI)中选择用于局部导航的中间航路点。
机器人不仅需要被引导前往目标,还必须在行进过程中探索周围环境,以便在遇到死路时能够识别出可能的替代路径。
鉴于没有预先提供的环境信息,所有可能的 POI 必须从机器人当前的周边环境中提取,并存储在内存中以供后续使用。
如果在后续步骤中发现某个兴趣点(POI)位于障碍物附近,则该点会从内存中删除。
在机器人已经访问过的位置,激光雷达不会再提取新的 POI。
此外,如果某个 POI 被选为航路点但在若干步内始终无法到达,它也会被删除,并重新选择一个新的航路点。
获取新的POI的方法:就是上面提到的POI的确定
从当前环境中提取POI,蓝色圆圈表示通过相应方法提取的兴趣点,绿色圆圈表示当前的航路点。
(a) 蓝色 POI 是通过激光雷达测距数据之间的间隙提取的;
(b)蓝色 POI 是从非数值型的激光读数中提取的。
在时刻 t,从当前可用的兴趣点(POI)中,使用基于信息的距离受限探索方法(Information-based Distance Limited Exploration,简称 IDLE)来选择最优的航路点。IDLE 方法通过以下方式评估每个候选 POI 的适应度:
$$
h(c_i) = \tanh\left(\frac{e^{\left(\frac{d(p_t, c_i)}{l_2 - l_1}\right)^2}}{e^{\left(\frac{l_2}{l_2 - l_1}\right)^2}}\right) l_2 + d(c_i, g) + e^{I_{i,t}}
\tag{1}
$$每个候选兴趣点 c (索引为 i) 的得分 h 由三部分组成
其中,机器人在时刻 t 的位置 p_t 与候选兴趣点 c_i 之间的欧几里得距离分量 d(p_t, c_i) 被表示为一个双曲正切函数(tanh)形式:
$$
\tanh\left(\frac{e^{\left(\frac{d(p_t, c_i)}{l_2 - l_1}\right)^2}}{e^{\left(\frac{l_2}{l_2 - l_1}\right)^2}}\right) l_2
\tag{2}
$$其中,e 是自然对数的底(欧拉数),l_1 和 l_2 是两个距离阈值,用于对得分进行衰减。这两个距离阈值根据深度强化学习(DRL)训练环境的区域大小设定。 这部分是一个距离惩罚项
注:
分子中指数部分的 d(p_t,c_i)/(l_2 - l_1) 这是在对距离 d 做归一化处理,把距离尺度转化为无单位的比值,l_2 - l_1 是距离窗口,也就是期望 d 落在这个区间里,这样做的目的是让距离 d 的大小相对于“允许的距离范围” (l_2 - l_1) 来表达,而不是绝对距离大小,方便在指数和平方计算中保持数值的合理范围。
l_2 / (l_2 - l_1) 是对 l_2 进行归一化处理,这个值确定了指数表达式的“最大值”或者“参考值”,它让指数中的分子和分母在相同的尺度下进行比较,实现对距离得分的合理缩放和归一化。本质上也是实现了e^x / e^y 这个分式的归一化处理。
通过平方,可以让距离差异更敏感,远离阈值的点权重变化更大。
通过指数放大这个变化,距离较远或较近的点的得分迅速减小或增大,达到对距离分量的平滑衰减效果。
这种平滑衰减避免了距离直接线性权重导致的极端值影响,使得分分布更合理和稳定。
使用双曲正切函数 tanh() 将指数结果映射到 (0, 1) 之间,起到非线性缩放和平滑归一化的作用。
最后乘以 l_2 对距离分量进行尺度调整,映射到 (0, l_2)之间
这一部分得到的值,是一个非线性压缩过的距离得分项,目的就是使距离处于 l_1~l_2 之间的候选兴趣点的得分平滑上升,有利于选点策略更稳定
第二个分量 d(c_i, g) 表示候选兴趣点 c_i 与全局目标点 g 之间的欧几里得距离(全局目标距离)。
最后,时刻 t 的地图信息得分(信息增益激励项)表示为:
$$
e^{I_{i,t}}
\tag{3}
$$其中,I_{i,t} 的计算方式如下:
$$
I_{i,t} = \frac{\sum\limits_{w=-\frac{k}{2}}^{\frac{k}{2}} \sum\limits_{h=-\frac{k}{2}}^{\frac{k}{2}} C(x+w)(y+h)}{k^2}
\tag{4}
$$其中,k 表示用于计算候选点周围信息的卷积核大小,候选点的坐标为 x 和 y ,而 w 和 h 分别表示卷积核的宽度和高度。
在公式 (1) 中,具有最小 IDLE 得分的兴趣点(POI)被选为用于局部导航的最优航路点。
注:
I_{i,t} 表示候选兴趣点(POI)c_i 在时间 t 的信息得分,它用于衡量此点周围环境的“信息丰富度”或“探索潜力”,得分越高,说明此 POI 附近还有未探索、未知或值得探索的区域。
C(x, y) 是地图上 (x, y) 点的置信值或不确定度值,可能来源于占据栅格地图中的熵值、不确定度、未知区域标记、置信概率等,通常,这个值越高,表示该位置的信息越少、越值得探索。
双重求和:它是在点 (x, y) 的周围取了一个大小为 k * k 的滑动窗口,然后对该窗口内所有位置的 C 值进行求和,也就是在以候选点为中心的邻域中,统计该邻域“信息量”。
除以 k^2 是做了一个均值操作,即把窗口内的信息总量归一化为平均信息值,得到的值落在 [0, 1]内,便于指数函数处理。
其目的就是鼓励探索未知区域
注意到,h 的三个组成部分好像不能直接相加,第一部分得到的是一个得分值,第二部分是一个距离值,第三部分是一个信息增益激励值,貌似是不能直接相加的,但第一部分进行了一个 *l_2 的操作,是一个伪距离,最后一部分也进行了指数化操作,所以是可以相加的
B.局部导航
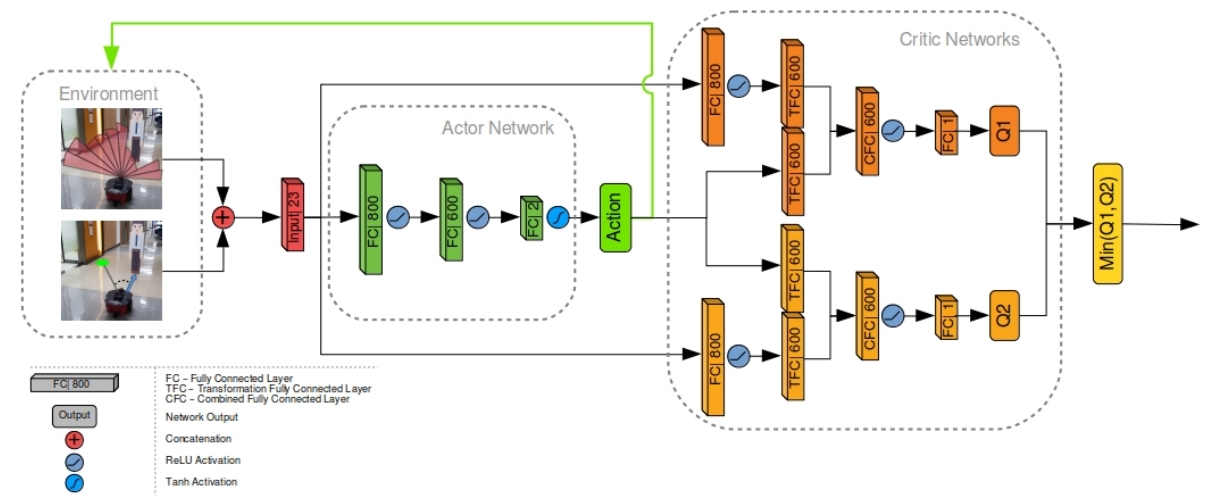
使用基于 双延迟深度确定性策略梯度(TD3,一种 Actor-Critic 架构)的神经网络架构来训练运动策略
局部环境信息和目标航点相对于 agent 位置的极坐标一起,作为状态输入 s 传入 TD3 的Actor 网络中
该 Actor 网络由两个全连接(FC)层组成,每一层后面都接有 ReLU(修正线性单元)激活函数。
最后一层与输出层相连,输出两个动作参数 a,分别表示机器人的线速度 a_1 和角速度 a_2
输出层采用 tanh 激活函数,将输出限制在区间 (−1,1) 内
在将动作应用于环境之前,它们会按以下方式缩放为实际速度值:
$$
a = \left[ v_{\max} \left( \frac{a_1 + 1}{2} \right), \omega_{\max} a_2 \right],
\tag{5}
$$最大线速度 v_max,最大角速度 ω_max
由于激光雷达只记录机器人前方的数据,因此不考虑向后的运动,并将线速度调整为仅为正值。
状态-动作对的 Q 值 Q(s,a) 由两个 Critic 网络进行评估。这两个 Critic 网络具有相同的结构,但其参数更新是延迟进行的,从而允许它们在参数上产生差异(避免完全同步)。
Critic 网络以状态 s 和动作 a 的组合作为输入
其中,状态 s 首先被送入一个全连接层,并接上一个 ReLU 激活函数,输出为 L_s
该层的输出 L_s 以及动作 a,将分别送入两个大小相同的变换全连接层(TFC)中,分别对应变换结果为 τ1 和 τ2,随后,这两个结果按如下方式进行组合:
$$
L_c = L_sW_{\tau_1} + aW_{\tau_2} + b_{\tau_2},
\tag{6}
$$其中,L_c 是组合全连接层(CFC)的输出,W_τ_1 和 W_τ_2 分别是 τ1 和 τ2 的权重,b_τ_2 是 τ_2 的偏执项,然后在这个组合层上使用ReLU激活函数,接着,该输出连接到一个最终输出节点,该节点包含一个参数,表示对应状态-动作对的 Q 值。最终,从两个 Critic 网络中选择较小的 Q 值,作为最后的 Critic 输出,以此来限制对状态-动作值的过高估计。
完整的网络架构如图
TD3 网络结构包括 actor 和 critic 两个部分。每一层的类型以及其对应的参数数量在层中都有描述。TFC 层指的是变换全连接层 τ,CFC 层指的是组合全连接层 Lc。
策略的奖励依据以下函数进行评估(奖励函数)
$$
r(s_t, a_t) =
\begin{cases}
r_g & \text{if } D_t < \eta D \
r_c & \text{if collision} \
v - |\omega| & \text{otherwise},
\end{cases},
\tag{7}
$$在时间步 t时,状态-动作对 (s_t, a_t) 的奖励 r 取决于以下三种情况:
如果当前时间步与目标点的距离 D_t 小于阈值 η_D,则给予一个正的目标奖励 r_g(也就是鼓励)
如果检测到碰撞,则给予一个负的碰撞惩罚 r_c(惩罚)
如果以上两种情况均未发生,则根据当前的线速度 v 和角速度 ω 给予即时奖励。
为了引导导航策略朝向给定目标,一个延迟归因奖励方法被采用,其计算如下:
$$
r_{t-i} = r(s_{t-i}, a_{t-i}) + \frac{r_g}{i}, \quad \forall i \in {1, 2, 3, \ldots, n},
\tag{8}
$$其中,n 表示前 n 个时间步中需要更新奖励的步数。这意味着,正的目标奖励不仅被分配给达到目标的那个状态-动作对,还以递减的方式分配给其之前的 n 个时间步。通过这种方式,网络学习到了一种局部导航策略,该策略能够仅依赖激光输入,避开障碍物的同时到达局部目标。
C.探索与建图
机器人沿着路径点被引导向全局目标前进。一旦靠近全局目标,机器人将自主导航至该目标。在此过程中,环境被逐步探索和建图。建图依赖于激光雷达和机器人里程计传感器数据,生成环境的占据栅格地图。完整的自主探索与建图算法的伪代码在算法1中进行了描述。

实验部分
算法过程:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
global_goal # 全局目标点,即最终导航的目标位置
δ # 导航至全局目标的距离阈值,用于判断机器人是否“足够接近”目标点
# 主循环 直到达到全局目标
while(reached_global_goal != True){ # 判断是否已达到全局目标
read sensor data # 读取传感器数据:如激光雷达、相机、里程计等
update map from sensor data # 根据传感器数据更新地图:构建或完善占据栅格地图
Obtain new POI # 获取新的兴趣点 POI,可能是探索边界或未知区域的候选目标点
# 判断当前是否已接近目标区域
if (D_t < δ_D){ # 如果 agent与目标的距离处于接近目标区域
if(waypoint = global_goal) # 若当前导航的子目标 waypoint 已经是 global_goal
reachedGlobalGoal = True # 那么任务完成
else{ # 否则,进一步判断当前是否靠近全局目标
if(d(p_t, g) < δ) # 如果当前位置p_t与目标g的距离d(p_t,g) 小于 δ
waypoint <-- global_goal # 那么就把当前的 waypoint 设置为 global_goal
else # 否则,从所有兴趣点中选择下一个最优子目标点
for i in POI # 遍历POI中所有的兴趣点
caculate h(i) from (1) # 根据式子(1)计算每个兴趣点的启发值h(i)
waypoint <-- POI_min(h(i)) # 将h(i)值最小对应的兴趣点作为新的 waypoint
end if
end if
end if
Obtain an action from TD3 # 从 TD3 策略网络中获取当前动作,利用强化学习模型TD3预测最优动作
Perform action # 执行该动作
end whileA.系统设置
原作者系统配置:
显卡:NVIDIA GTX 1080
运行内存:32G
CPU: Intel Core i7-6800K
训练参数设置
TD3网络在Gazebo上进行训练,并通过ROS进行控制,训练了800回合,约8h
每个训练回合在机器人到达目标、发生碰撞或执行了 500 步动作后结束
最大线速度 v_max 和最大角速度 ω_max 分别设置为 0.5 m/s 和 1rad/s
延迟奖励在最后 n=10 步中更新,参数更新延迟设置为每 2 个回合
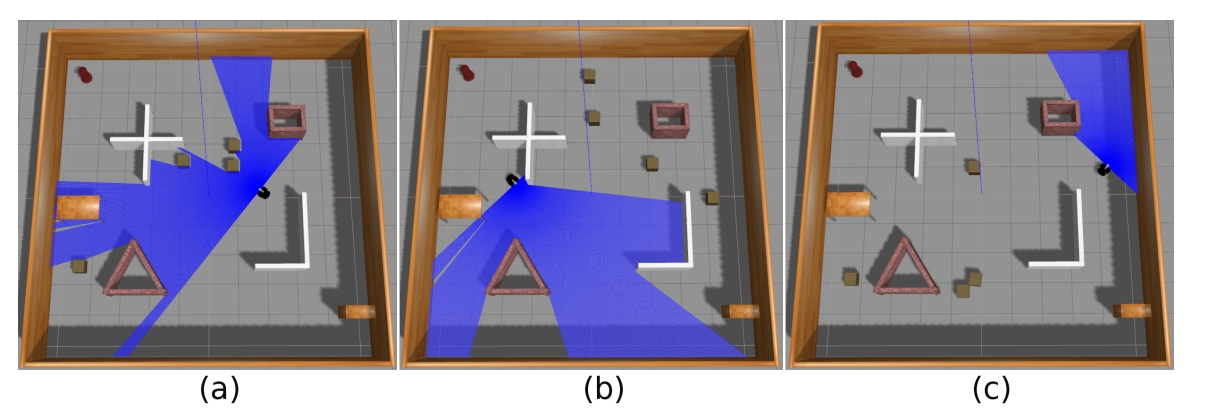
训练在一个 10x10 米的模拟环境中进行,如图所示
训练环境示例。蓝色区域表示输入的激光雷达读数和测距。四个箱形障碍物在每一轮训练中都会改变位置,如图(a)、(b)和(c)所示,以实现训练数据的随机化。
为促进策略的泛化与探索,向传感器读数和动作值中添加了高斯噪声。为了构建多样化的训练环境,在每个回合开始时,箱形障碍物的位置会被随机化。其位置变化的示例如图 (a)、(b)、(c) 所示。同时,机器人的起始位置与目标位置也在每一回合中被随机设置。
ROS 中的 SLAM Toolbox 软件包用于生成和更新环境的全局地图,并用于机器人在地图中的定位
ROS的本地规划器包(TrajectoryPlanner)代替了神经网络
目标驱动自主探索(GDAE, Goal-Driven Autonomous Exploration)
最近前沿探索策略(Nearest Frontier, NF)
目标驱动强化学习(GD-RL, Goal-Driven Reinforcement Learning)
本地规划器自主探索(LP-AE,Local Planner Autonomous Exploration)
路径规划器(PP,Path Planner)它是基于 Dijkstra 的生成路径的方法
B.定量实验
C.定性实验
结论
基于深度强化学习(DRL)的目标驱动型全自主探索系统(GDAE)
无需人工干预,即可导航至指定目标并记录环境信息(导航去目标点的过程中建图)
系统有效结合了反应式的本地导航策略和全局导航策略
将神经网络模块引入端到端系统:机器人无需生成显式路径即可移动,而这一机制的不足则通过引入全局导航策略得到了弥补
系统的导航性能接近于基于已知地图路径规划器所得的最优解
GDAE 系统依赖直接的传感器输入而非从不确定地图生成路径,因此在可靠性方面表现更佳
若希望进一步泛化至不同类型的机器人,可以将机器人动力学作为神经网络的一个输入状态,并据此开展训练。只需提供机器人动力学信息,即可在不同平台上实现最优的本地导航。
接下来的研究:
引入长短时记忆(LSTM)结构也可能有助于缓解局部最优问题,并辅助规避当前传感器视野之外的障碍物
代码部分
两个量的定义
Episode:
它是后续步骤的集合,直到达到其中一个终止条件(终止条件:达到目标、与障碍物碰撞或达到最大步数max_ep)
它可以理解是一个训练过程,如果达到终止条件就开始新的一个训练过程,并且伴随着环境的改变,包括区域内的墙体位置改变、障碍物的位置改变、agent的初始位置改变和目标点位置的改变
Epoch:
执行评估之间的后续事件数(episode)或者时间步长(timesteps)
一个epoch运行5000个步骤step(对应代码中的 eval_freq 这个参数),步长为0.1秒,也就是说一个epoch大概要运行8分多钟